哪些场景需要 SSR 服务
现如今 Web 前端的主流 UI 框架都是 React 和 Vue,以及 Angular,这些框架主流的做法都是在客户端基于 JS 来完成 HTML 内容结构的渲染。对于一些 HTML 内容结构主要由动态数据构成的复杂页面,在性能表现一般的移动设备上渲染的计算就会显得有点吃力,那么此时如果有 SSR 服务在服务端完成 HTML 内容结构的渲染,可以显著提升渲染的性能。
当然还有页面需要做 SEO 的场景,不过这不是本文想要表述的范畴。
为什么要搭建通用的 SSR 服务
其实对于 React 或 Vue 都有相应的开箱即用的框架,可以提供现成的 SSR 服务,但单纯为了使用 SSR 服务而去使用这些框架就会有点重,还会对前端的整体架构有诸多限制,并且 SSR 的性能在这些框架中应该还有进一步压榨的空间。
对于前端应用来说,SSR 服务应该是一个可选项,只对性能敏感的页面开启,所以 SSR 服务与前端的应用尽量不要耦合在一起,同时为了确保 SSR 服务的性能,也尽量不要在服务中耦合其他乱七八糟的功能。
如果团队中既有 React 又有 Vue,在一个 SSR 服务中同时满足 React 和 Vue 的支持也是可行的。
所以一个通用的 SSR 服务应该尽量和前端应用在架构设计上保持松耦合,保持功能的单一性,如果团队确实需要,可以同时支持 React 和 Vue。
SSR 的核心流程
SSR 本质上是把在客户端完成 HTML 内容结构的渲染输出的工作迁移到了服务端。对于现代的前端框架 React 和 Vue,它们都支持同构的渲染,这意味着可以直接将 React 和 Vue 的 JavaScript 代码放在由 Node.js 编写的服务端上运行。
一般来说「HTML 内容结构的渲染输出」的结果应该是“动态”的,比如每个用户请求的页面内容是不一样的,或者每隔一段时间内容就会更新等。如果是一个纯静态的页面,那么 SSR 的意义也不大,因为这完全可以采用预渲染的方案,而不是在每次请求时才去做渲染输出。
动态的 HTML 内容结构的渲染输出意味着需要在服务端完成首屏数据的请求,对于非首屏数据,可以在客户端进行按需加载。
那么 SSR 服务主要做的事就是当请求页面时预请求好首屏数据,然后再使用首屏数据去填充应用来生成 HTML 内容,最终将 HTML 内容传输给客户端。
当一个页面请求到达 SSR 服务端时,总结 SSR 的核心流程如下: 1. 服务端:请求应用首屏数据。 2. 服务端:将首屏数据填充到应用中,运行服务端渲染,生成 HTML 内容。 3. 前端:基于服务端响应的 HTML 内容来“激活”应用。
用户最终感知到的渲染时间轴如图。
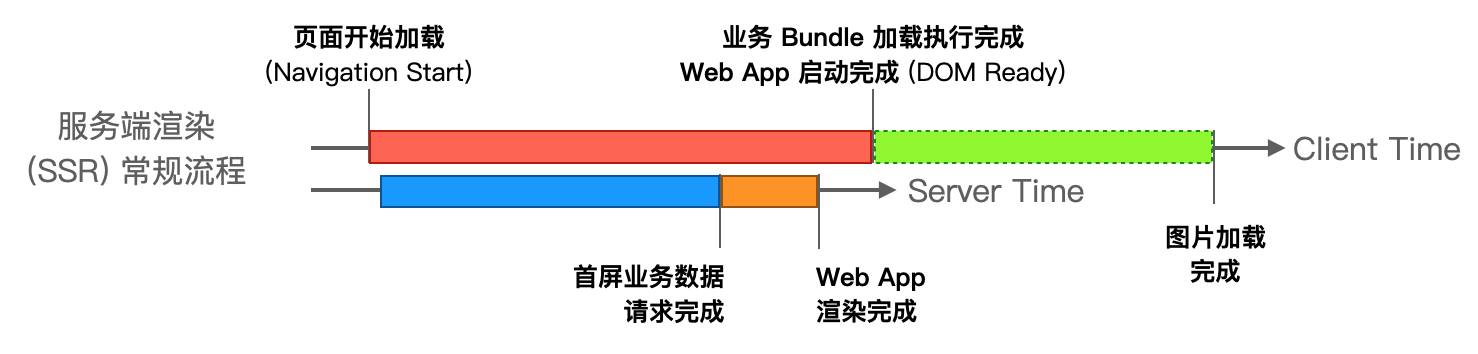
基于以上的核心流程,我们来一步步展开细说流程中面临的挑战。
请求首屏数据
通常来说,应用的首屏数据请求是耦合在应用常规的业务代码中,需要将耦合的请求参数和条件抽取成独立的模块 getInitData ,以方便服务端进行调用。
getInitData 提供的是发起首屏数据请求的参数,而不是具体的请求方法,因为前端的 Ajax/Fetch 无法直接在 Node.js 服务端环境中运行,Node.js 中对应的是 http.request,不过有些网络请求库像 Axios 由于封装得当可以跨端运行。同时首屏的请求可能会有多个,甚至相互之间还可能存在依赖等,需要注意标准化的抽象。抽象如果比较合理,其实 getInitData 也可以是一个同构的模块,可以同时运行在客户端和服务端。
在客户端基本只会使用 HTTP 协议来请求首屏数据,但是在服务端其实有更多选择,除了 HTTP,还可以使用 RPC,这样在服务间的调用会更高效。
getInitData 在设计时可以做到宿主无关,以及协议无关,一个典型的样例如下:
// getInitData.js
function getInitData() {
return {
example: {
url: "/api/example",
method: "get",
responseValidator: function(res) {
return res.code === 0
}
}
};
}
module.exports = getInitData;运行服务端渲染
请求完首屏数据,就可以开始将首屏数据填充到应用中,这里就开始涉及到前端应用在服务端开始运行的流程了,情况逐渐复杂,这里会面临一些问题。
避免宿主环境被“污染”
由于宿主环境的差异,前端的应用在服务端运行时可能会从 window 读取一些全局变量或环境信息,而在 Node.js 运行环境中是没有 window 环境的,当然可以在运行前提前 Mock 出一个包含简版 BOM 的 window 环境,DOM 环境就不要想了。
既然有读的问题,那就无法避免的会有全局变量往 window 写入全局变量的问题,如果不做处理直接运行时就会“污染”服务端的环境,可能有人会说,污染就污染吧,能有什么影响呢?实际上影响可能非常严重,每一个 HTML 请求是要做无状态化的,如果在请求时会往一个全局命名空间中写入一些数据,然后再读取,那么并发请求时,就变成了一个有状态的请求,那就全乱套了。
// 请求 A 写入并读取数据
/GET a.html
window.foo = 'a';
// 请求 B 与 A 同时发生
/GET b.html
window.foo = 'b';
// 这时的 window.foo 就变成了一个“薛定谔的 foo”要解决环境污染的问题,其实就需要引入沙箱,在 Node.js 中提供的 vm 模块就是用于沙箱的。
在请求发生时,构造一个沙箱环境,往沙箱环境里写入一个 Mock 的 window 环境,然后让应用在沙箱里运行。
const vm = require('vm');
const getInitData = require('./getInitData');
// 创建沙箱的运行上下文环境
let vmContext = {
window: {
// 写入一些常用的数据,如 cookie、UA 等
document = {
cookie: '...'
},
// Mock setTimeout 0
setTimeout = function(fn, timeout) {
if (!timeout) {
fn();
}
};
}
};
// 运行 getInitData 获取首屏请求的参数
const requestConfig = getInitData();
// 请求首屏数据
let ssrData;
try {
// 请求首屏数据
ssrData = await request(requestConfig);
}
catch (error) {
console.error('got request error', error);
}
// 将首屏数据注入到沙箱的 window 中
vmContext.window.ssrData = ssrData;
// 将应用包的代码使用沙箱进行编译
const renderScript = new vm.Script(renderScriptCode);
// 服务端渲染的结果
let htmlContents;
try {
// 运行沙箱中的代码
htmlContents = renderScript.runInNewContext(vmContext, {
timeout: 500
});
} catch (error) {
console.error('got render error', error);
}
process.nextTick(() => {
if (vmContext) {
// 清理沙箱环境
clearContext(vmContext);
vmContext = null;
}
});renderScriptCode 就是 React 的整个应用包,包含了 React 基础库和业务代码,同时在 renderScriptCode 中还会调用 renderToString 来真正运行服务端渲染。
function createRenderScriptCode () {
return `
(function () {
${contents};
return window.ssrContext.ReactDOMServer.renderToString(window.ssrContext.entryApp);
})();
`;
}沙箱环境的构建以及将应用放到沙箱中运行时有一些需要注意的点。
* 应用代码中可能存在 setTimeout 0 的情况(如Vue2的基础框架代码),这里把 setTimeout 转成了立即执行的函数。
* Node.js 的 global 也会有全局的对象(如String/Number)或函数(如setTimeout),如非必要尽量不要将其注入到沙箱中,可直接使用沙箱中的 global,不要使用 Node.js 运行时的 global。因为不同宿主环境的 API 可能会存在差异。如 window.String = global.String 就是多此一举且可能引起 React + Recoil 在执行渲染时出现异常。
* 在沙箱运行完后,建议对沙箱进行清理,且清理动作最好在 process.nextTick 中运行。
由于不同宿主环境的 EventLoop 以及全局 API 的实现存在差异,在沙箱中运行的代码应尽量注意这方面的使用和处理,尤其是涉及到 setTimeout 0 和 Promise.resolve(true) 这类场景。
合理的预编译缓存
上面沙箱代码的创建和运行是在每次 HTML 请求发生时的处理流程,这也意味着每个请求都要创建一个沙箱,总归来说沙箱的创建和运行都会有一定的开销,运行环节省不掉,但是创建其实可以提前处理,这就涉及到前端应用包的预编译。
在 Node.js 服务启动时就可以做预编译,当应用包需要更新时再更新预编译的沙箱内容。
分块渲染的实现
在上面主要讲了首屏数据请求以及在沙箱中运行服务端渲染,读到这里,相信读者还会产生更多的疑问,如上面并没有看到服务端渲染的到底是怎么做的,先不要急,在前端实现部分将重点介绍,这里还有一个服务端必须要讲的重要环节,如果没了这个环节,整个服务端渲染的性能都会大打折扣。
分块渲染也有叫“流式渲染”的,实际上我在实现分块渲染时并不知道这个名词,而是我后来了解到我所在公司内部的其他 SSR 项目也用到了一样的优化实现,叫做流式渲染。
分块渲染主要用到了 HTTP 1.1 起就引入的特性分块传输:Transfer-Encoding: chunked。一般来说一个 HTTP 的请求只会响应一次,而分块传输允许一个 HTTP 的请求的连接中可以多次响应,在 SSR 的场景中,服务端在响应一个 HTML 页面的请求时至少可以拆分成两个分块:
* 静态 HTML 部分:无动态内容,包含静态样式、JS 脚本等,一般来说这是整个 页面中体积最大的部分。
* 动态 HTML 部分:服务端渲染出的动态 HTML 内容。
HTTP/1.1 引入的分块传输与 HTTP/2 的多路复用不是一种技术,不要混淆了,在 HTTP/2 中仍有分块传输的机制。
当然光有 HTTP 分段传输并不够,实际上还需要客户端的配合,在浏览器/WebView 中,还需要支持分段渲染,其实就是边加载边渲染。在 PC 浏览器上这并不是什么新特性,但是在移动设备上截止到发文时的实测结果来看,iOS 的 WKWebView 仍然不支持分段渲染,Android 的 WebView 是可以支持的。
哪怕有一端支持也是很大的提升,这意味着客户端在请求 HTML 页面时,它会先加载并渲染页面的骨架,而服务端同时在并行处理 SSR 的响应,当服务端处理完成,客户端获取到 SSR 响应的结果,再将响应结果追加到页面中,完成整体的渲染。为了优化加载体验,可以在等待服务端响应 SSR 的内容时,为静态页面增加一个骨架屏。
说到这里,Node.js 服务端的框架选型都还没介绍过,在 SSR 的场景中服务端框架承载的功能并不多,这里选用的是轻量级的 Koa,以 Koa 为例,来说明 SSR 分块渲染的实现。
ctx.set('Transfer-Encoding', 'chunked');
ctx.res.removeHeader('Content-Length');
ctx.body = createReadStream(staticHTML, getSSRInfo
());要在 Koa 中实现请求的分块传输,关键的三步是:
* 设置分块传输的响应头 Transfer-Encoding: chunked;
* 移除响应体的长度标识 Content-Length;
* 将响应体设置为一个可读流;
前两步主要是告知客户端服务端会使用分块传输,而分块传输中不能直接输出响应体的长度,而是以最后一个分块内容的长度为 0 来标记响应体结束。
createReadStream 函数首先会创建一个可读流,然后将 chunk 添加到压入流中,这个 chunk 就是静态的 HTML 部分,而 SSR 的处理结果就封装在 asyncTask 这个 Promise 函数中,处理的最后一步都会有 stream.push(null) 语句用来标记响应体为空代表响应的结束,没有这一步,响应就不能正确的结束。
function createReadStream(chunk, asyncTask) {
let stream = new Readable({
autoDestroy: true
});
const handleStreamCloseOrError = function(error) {
stream.removeListener('error', handleStreamCloseOrError);
stream.removeListener('close', handleStreamCloseOrError);
stream = chunk = null;
if (error) {
console.error(error);
}
};
stream.once('error', handleStreamCloseOrError);
stream.once('close', handleStreamCloseOrError);
stream._read = function() {};
stream.push(chunk);
if (typeof asyncTask === 'function') {
const handleTaskError = (error) => {
stream && stream.push(null);
console.error(error);
};
asyncTask().then((result) => {
if (stream) {
stream.push(result.data);
stream.push(null);
}
}).catch(handleTaskError);
} else {
stream.push(null);
}
return stream;
};至此,Node.js 服务端部分的设计和实现就到此结束了。
在前端“激活”应用
前端的 React 应用按照正常的客户端渲染流程需要调用 ReacDOM.render,而对于 SSR 来说,HTML 内容因为提前创建好了,不需要再由 ReactDOM 去创建,此时只需要“激活” React 应用即可,对应的 API 是 ReactDOM.hydrate,激活的操作是把 HTML 的结构与 React 应用建立起映射关系,方便后续的视图更新,同时绑定好事件。
有把
ReactDOM.hydrate翻译成水合的,这个翻译着实有点“水”,不过 API 本身的设计命名可能也有点飘了。
渲染降级
SSR 的渲染会有失败率的,比如首屏数据请求失败、执行渲染时出现未知的错误等,此时需要有渲染降级的措施,也就 SSR 失败后降级为 CSR(客户端渲染)。相当于在客户端做了一次重试,这样能尽可能提高渲染成功率,保证用户最终能看到正常的 UI 界面,这一步也很重要。
应用的入口文件需要同时支持 SSR 和 CSR。
window.ssrMount = fuction() {
// CSR
const doRender = () => {
ReactDOM.render(
entryApp,
document.querySelector(rootId),
callback
);
};
// SSR
const doHydrate = () => {
ReactDOM.hydrate(
entryApp,
document.querySelector(rootId),
callback
);
};
if (window.ssrData) {
doHydrate();
} else {
doRender();
}
}window.ssrData 是服务端请求好的首屏数据,通过判断当前运行时环境是否有这份数据来选择是否激活应用来完成 SSR 的最后一步,还是降级到 CSR。
前后端的衔接
window.ssrData 是在服务端注入到沙箱中的,光是这么注入,只能在沙箱的运行时环境有效,在客户端的运行时环境仍然获取不到,还需要进一步写入。同时 SSR 的结果也没有追加到页面中,这就涉及到 SSR 时的前后端衔接的处理。
服务端的数据要通过沙箱注入到客户端的运行时环境中,只要在 HTML 添加一个 script/textarea 标签,将数据写入到标签中,那么客户端在解析 HTML 时就能将获取到这些数据。
function ssrSuccessHtml ({ rootId, data, htmlContents }) {
// 动态 id 防冲突
const now = Date.now();
const ssrHtmlContentsId = `ssrHtmlContents-${now}`;
return `
<textarea id="${ssrHtmlContentsId}" style="display:none">${htmlContents}</textarea>
<script>
window.ssrData = ${JSON.stringify(data)};
document.getElementById("${rootId}").innerHTML = document.getElementById("${ssrHtmlContentsId}").textContent;
window.ssrMount && window.ssrMount();
</script>
`;
}- 使用 textarea 来写入 SSR 的结果;
- 然后在接下来的 script 语句中将结果字符串写入到 React 应用挂载的根节点;
- 执行
window.ssrMount来激活应用。
从 cookie 和 query 中解析出的内容直接在 JSON.stringify 后插入到 script 标签中无法防范 XSS 攻击,而使用 textarea 的方法存储 json 可防止 XSS 攻击,存储 html 字符串可规避字符转义的问题。
ssrSuccessHtml 是在服务端渲染的沙箱代码结束后运行来生成 HTML 的字符串,而 HTML 的代码解析和运行是在客户端收到 SSR 结果的分块时运行的。通过这种方式可以很方便的将服务端沙箱运行时环境的数据传输给客户端运行环境。
同时为了防止渲染运行失败,也应该提供相应的 ssrFailHtml 的函数,在这个函数中不输出 ssrData,但仍然调用 ssrMount,代码太简单就不贴了。
首屏数据的复用
虽然 SSR 的 HTML 字符串和 ssrData 都已经注入到了客户端的运行环境中,也通过调用 ReactDOM.hydrate 来激活了应用,但是如果不注意处理好首屏数据的复用,React 应用仍然会重新运行一遍客户端渲染。
因为按照正常的渲染流程,应用一般会在 create 或 mount 阶段去请求首屏数据,数据请求完后调用 setState 将数据注入到应用中,应用就会开始启动渲染的动作,而对于正常完成了 SSR 的应用,应判断是否存在 ssrData,通过复用 ssrData 来防止重复渲染。如果应用处理不当,那么 SSR 就白费了。
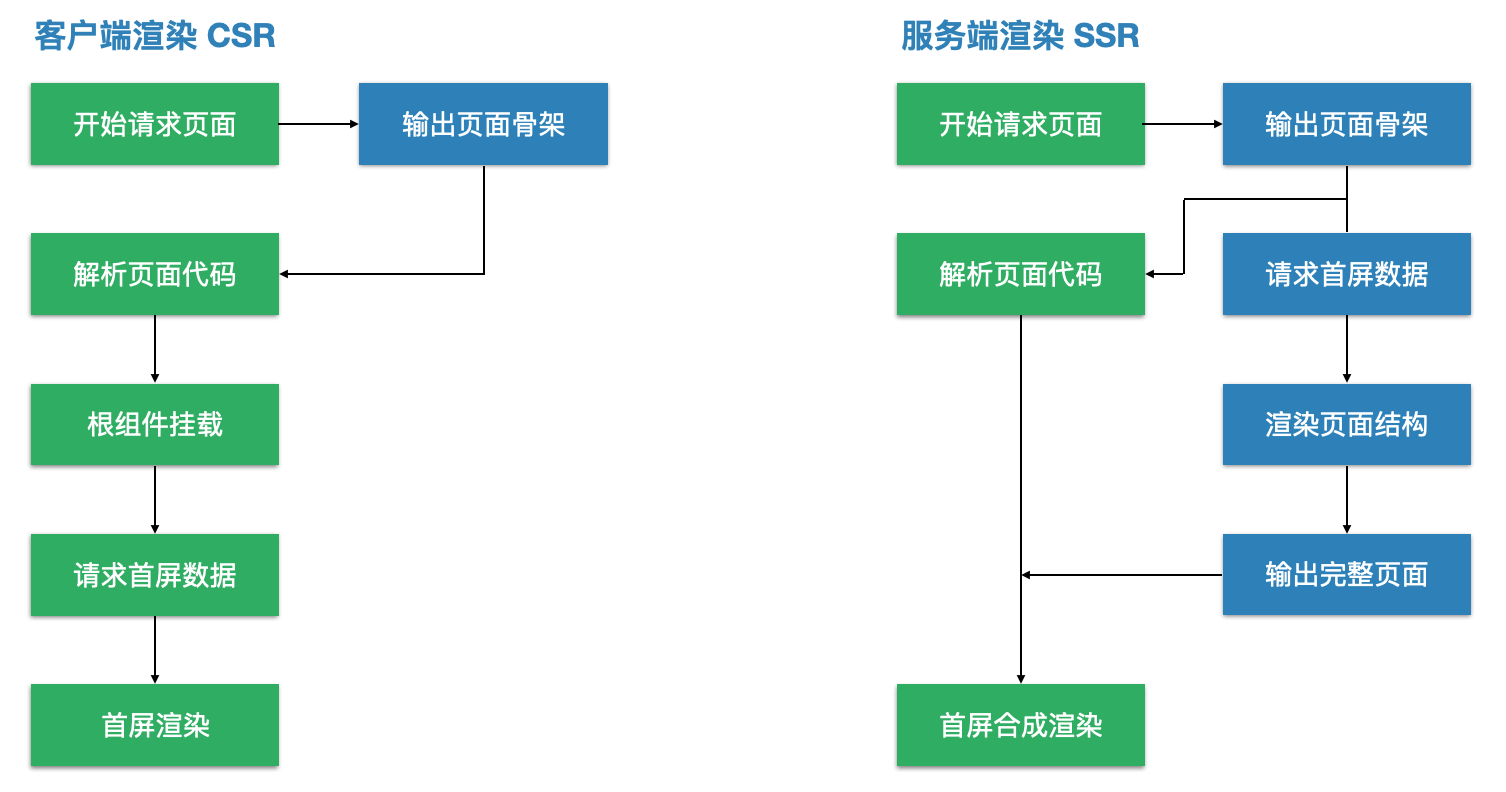
服务端渲染与客户端渲染的流程对比图。
前端编码的约束
以上已经介绍完了 SSR 的主要流程和关键细节,由于环境的差异对于要接入 SSR 的前端应用会有一些规范约束。无论是 React 还是 Vue,在执行服务端渲染时,应用并不会运行到 Mount 阶段(对应 React 的 componentDidMount 或 Vue 的 mounted),而在这个阶段之前,像是组件的实例化,create 等都尽量不要去读取和写入客户端环境特有的 DOM 和 BOM,实在要读取也确保在沙箱环境中已经做了 Mock,否则就会出现渲染失败。
常规的 DOM 和 BOM 访问其实很容易被发现,因为会直接报错。而对于 setTimeout 和 Promise 等异步执行的函数一旦使用了就容易出现一些意料之外的问题,它们不一定会报错,但是会导致内存泄漏,我就曾经遇到一个项目中比较隐式的使用了 setTimeout,排查内存泄漏的问题就花了大量的时间。
所以对于要接入 SSR 的应用,应该建立严格的规范约束,如果可以的话最好配合一些自动化的检测工具来做辅助。
Vue 的服务端渲染专门有文章介绍规范约束的注意点:Server-Side Rendering (SSR) | Vue.js,建议细读。
SSR 应用的构建编译
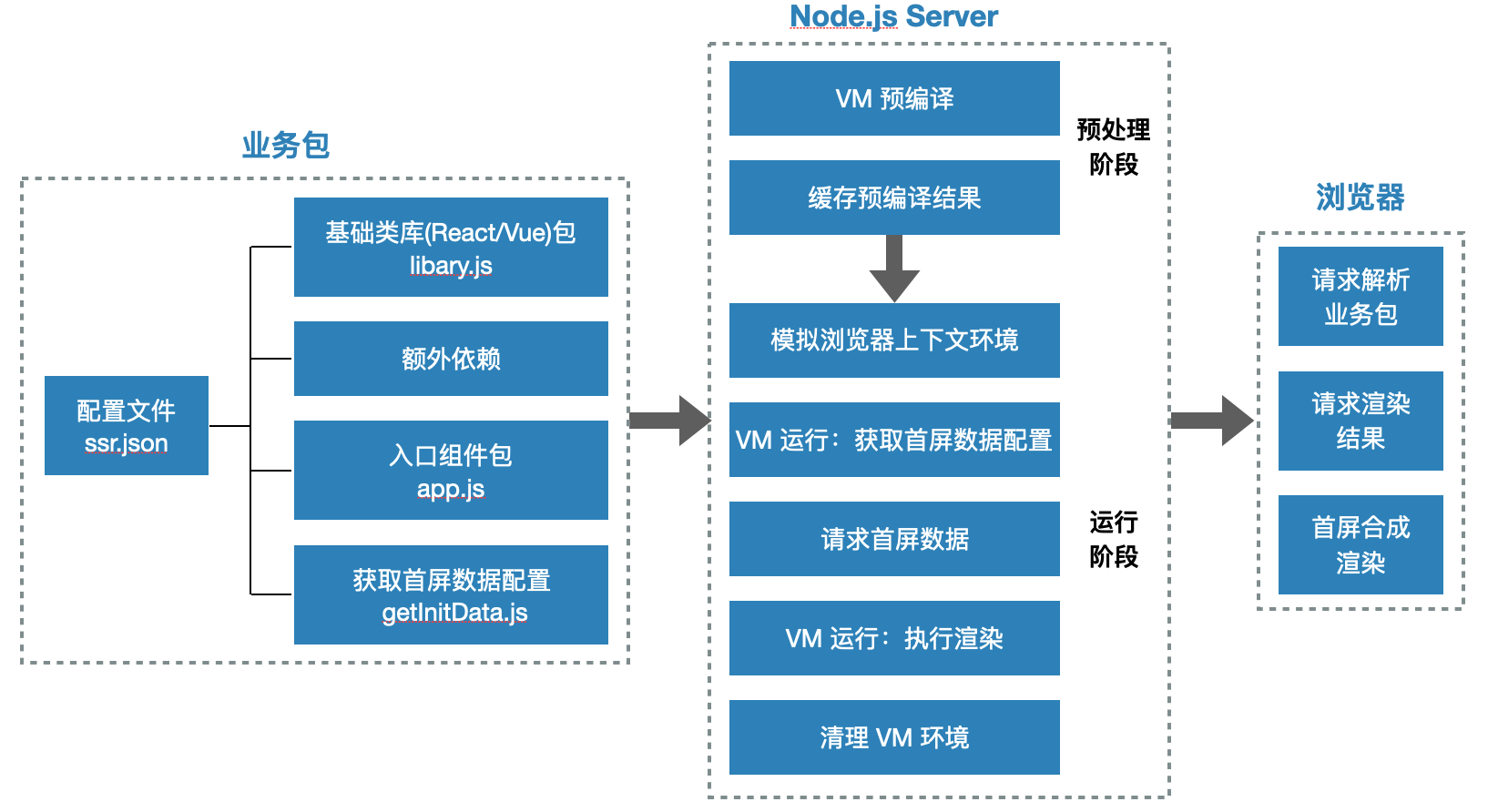
除了编码的约束,前端应用接入到 SSR 服务中也应该有工程化的规范约束。前端应用的包最终会部署到 SSR 服务上,服务通过读取约定的配置文件来将前端应用注册,一个典型的配置文件如下。
{
{
"index.html": {
"disable": false,
"type": "react",
"deps": [
"js/a.js",
"js/b.js"
],
"entryFile": "js/app.js",
"getInitDataFile": "ssr/get-initdata.js",
"serverRenderFile": "ssr/react.js"
}
}使用页面名称作为配置的 key,具体字段说明如下:
* disable 是否禁用 SSR
* type SSR 的类型
* deps 应用的依赖文件
* entryFile 应用的入口文件,入口文件应暴露入口组件和 React 的 API
* window.ssrContext.entryApp 入口组件
* window.ssrContext.ReactDOMServer React 服务端 API
* getInitDataFile 首屏数据请求参数函数
到这一步,从服务端到客户端的整体处理流程都介绍完了,最后用一个图做一下简单总结。
结语
要想搭建出一个高性能的通用 SSR 服务,确实有很多的点需要注意,涉及的相关技术有一定的深度也有广度,对于前端同学来说还需要具备 Node.js 服务的开发和运维经验,绝不是随便起一个服务把 SSR 跑起来那么简单,搞不好会起到负优化的作用,同时还有规范约束的建立,规范不到位引起的服务端内存泄漏排查起来会非常头痛,一旦出现内存泄漏,整个服务都会变得不稳定。
React v18 在服务端渲染的支持度比之前的版本更好了,这意味着对官方对服务端渲染的重视程度越来越高,也意味着在应用渲染性能的优化方案会越来越复杂。
文本介绍的 SSR 服务并未涉及到内容缓存的优化,同时为了避免服务本身的状态化,也可以将前端应用包托管到文件存储服务上,这里都不做过多介绍了,文章篇幅已经超了。
由于本文篇幅较长,超出了我一开始的预想,涉及到的内容也比较杂,相关演示代码也都是伪代码,难免疏漏,还望见谅。